Overview
For today's lab, we will create a model to simulate Hardy-Weinberg Equilibrium. Remember that HW Equilibrium means no change in allele frequencies over time. Your population can (probably should) start out of HW proportions but should attain them after one generation of random mating. This model will be the basis for models we build in the upcoming weeks. For example, next week we'll take this basic HW model and modify it to allow for genetic drift. You may wish to refer to the textbook or other resources to help you remember the meanings of equations, etc.
Open VensimPLE. It may be helpful to refer to last week's handout or your notes to help you remember where things are, etc.
Modeling Hardy-Weinberg Overview
Before starting the model, think about what we are trying to do. What happens in the HW model? For an example, consider a population of mussels that reproduce by broadcast spawning: once a year, individuals release their gametes into the water column, where they meet up with other gametes at random and undergo syngamy to form a new zygote (see figure).
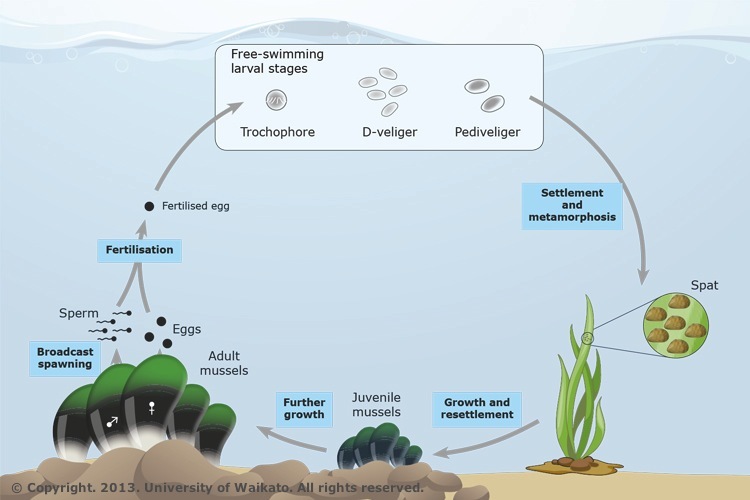
Figure 1. The life cycle of the New Zealand green-lipped mussel (Perna canaliculus, kütai). As larvae, green-lipped mussels are free-swimming. They metamorphose and settle onto seaweed and subsequently onto solid surfaces.
In nature, many mussels are iteroparous (spawning more than one reproductive episode in their lifetimes) but for the sake of our simple model, we're going to assume they are semelparous (they reproduce once and then die) Each individual in the population produces gametes (via meiosis), spews them out into the water column, and then dies (so we are modeling them as annuals, discrete non-overlapping generations). The gametes fuse into diploid zygotes (probabilistically, at random), spend some time as planktonic larva, and then settle on a hard surface where they grow into adult mussels. The next year, those adult mussels spew their gametes into the water and then die, etc (the circle of life...).
In our model, the number of Adults represents the total population size (N). It's the life stage that we are tracking from one generation to the next. We're also going to model the simplest base case, one locus with two alleles. We will have three genotypes, which is like having 3 different kinds of Adult mussels, each represented by a separate stock box. The mussels with each genotype will produce gametes (every individual produces the same number of gametes, no selection!). Those gametes will be joined at random (following binomial probabilities) to form the next generation of adults. For each generation, we will want to examine the observed genotype frequencies (based on the stocks), the allele frequencies (calculated from observed geno frequencies), and the HW expected genotype frequencies (calculated from allele frequencies).
When we create the new generation of mussels, we will do so following HW expectations, using the allele frequencies of gametes to determine how many zygotes of each genotype are formed. Note that we're going to assume the population size is not being affected and that it's large, we'll use N = 10000 for the total population in our example. And because we're examining HW, which occurs quickly, we'll use just 10 time steps (generations).
Building the Hardy-Weinberg Model
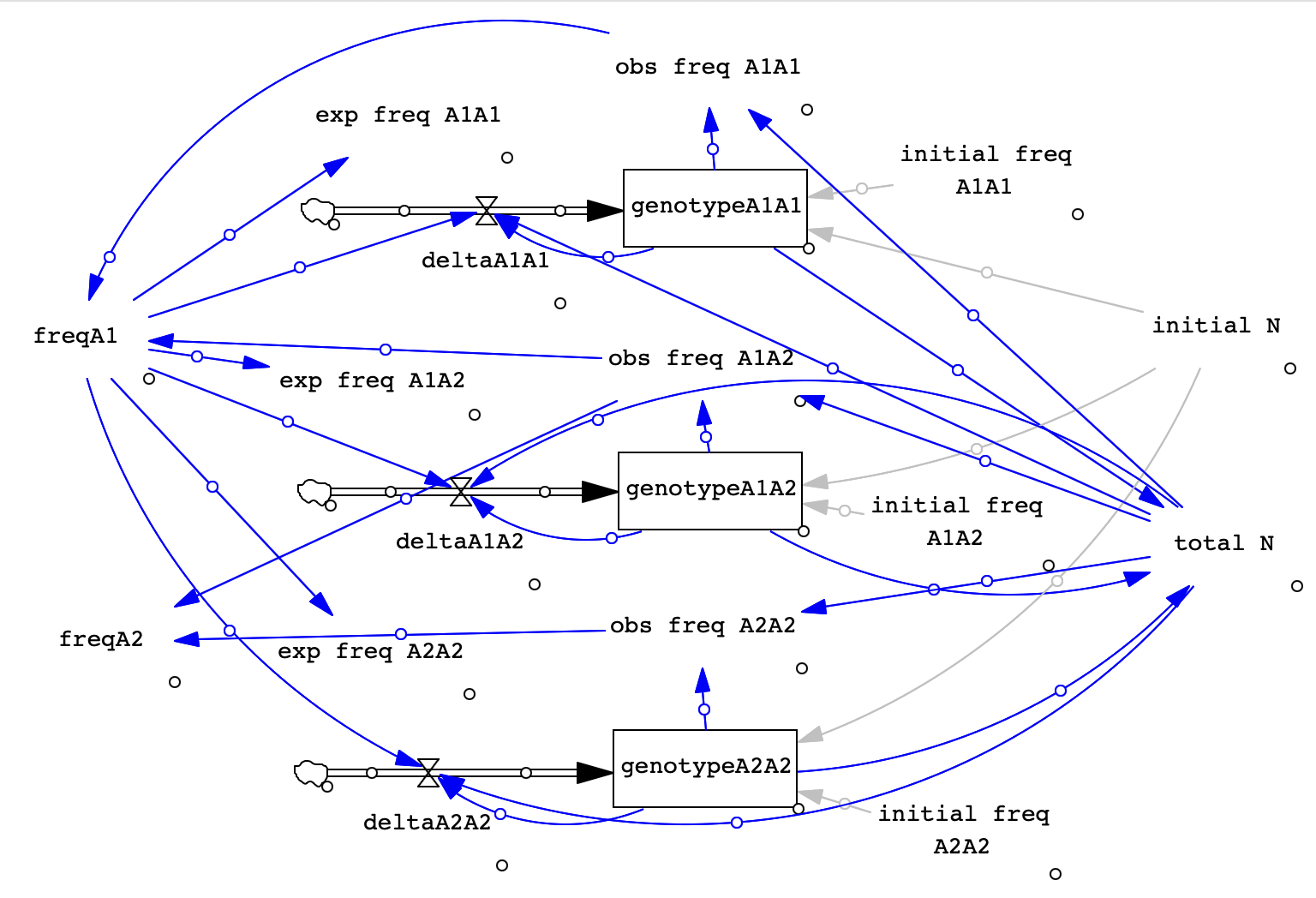
For your reference, we're going to create 1 stock for each genotype. Each stock will have a flow to allow us to add new individuals in the next generaton. Each stock will also be set up to be Discrete, emptying out at the end of a time step (b/c all adults die after reproducing). We will also set up variables to keep track of total population size, observed genotype frequencies, allele frequencies, and expected genotype frequencies. Finally, we will want one graph to show geno- type frequencies and one to show allele frequencies. Below is an image of the completed model for you to reference.
- Open a new model and input the following settings:
| Units for Time |
Year |
| INIITIAL TIME = |
0 |
| FINAL TIME = |
10 |
| Time Step |
1 |
- First, set up your stocks for each genotype. Click the Stock icon and then click in the Build Window. Name the first one ‘genotypeA1A1' to denote that it will keep track of how many individuals have the genotype. A1A1. Now set up stocks for the other two genotypes. Like in the image, leave some space around each for you to add other components.
- Remember that these boxes will contain a number of individuals of each genotype, not a frequency.
- Set up a flow into each stock, which you should name ‘deltaA1A1', ‘deltaA1A2', and ‘deltaA2A2'. Delta means change and these flows will calculate how many new zygotes there are of each genotype, each generation. Go ahead and make a single flow into each stock. Make sure the black arrow points into your stock, not away from it.
- To allow us to easily change the size of our population and figure out how many of each individual to start with, we'll create a Variable called 'inital N'. Click the Variable icon and then click in the Build Window to create this variable, name it 'initial N'.
- Create the rest of the variables in this list. You just need to place them in the model and name them for now. We'll finish set up when we enter equations.
- initial freq A1A1 -- this will set up the starting frequency of the A1A1 genotype.
- initial freq A1A2 -- this will set up the starting frequency of the A1A2 genotype.
- initial freq A2A2 -- this will set up the starting frequency of the A2A2 genotype.
- total N -- keeps track of population size for us
- obs freq A1A1 -- the freq of A1A1 in our population.
- obs freq A1A2 -- the freq of A1A2 in our population.
- obs freq A2A2 -- the freq of A2A2 in our population.
- freqA1 -- frequency of the A1 allele in our population.
- freqA2 -- frequency of the A2 allele in our population.
- exp freq A1A1 -- the frequency of A1A1 that we expect from HW given the allele frequencies.
- exp freq A1A2 -- the frequency of A1A2 that we expect from HW given the allele frequencies.
- exp freq A2A2 -- the frequency of A2A2 that we expect from HW given the allele frequencies.
- Now that we have all our components set up, we can connect them with arrows. Use the image above as a guide for where to place your arrows. This list may also help:
| Variable |
Arrow pointing to |
Arrow arriving from |
| genotypeA1A1 |
total N; obs freq A1A1; deltaA1A1 |
initial freq A1A1; initial N |
| genotypeA1A2 |
total N; obs freq A1A2; deltaA1A2 |
initial freq A1A2; initial N |
| genotype A2A2 |
total N; obs freq A2A2; deltaA2A2 |
initial freq A2A2; initial N |
| initial freq A1A1 |
genotypeA1A1 |
none |
| initial freq A1A2 |
genotypeA1A2 |
none |
| initial freq A2A2 |
genotypeA2A2 |
none |
| initial N |
genotypeA1A1; genotypeA1A2; genotypeA2A2 |
none |
| total N |
obs freq A1A1; obs freq A1A2; obs freq A2A2; deltaA1A1; deltaA1A2; deltaA2A2 |
genotypeA1A1; genotypeA1A2; genotypeA2A2 |
| obs freq A1A1 |
freqA1 |
genotypeA1A1; total N |
| obs freq A1A2 |
freqA1; freqA2 |
genotypeA1A2; total N |
| obs freq A2A2 |
freqA2 |
genotypeA2A2; total N |
| freq A1 |
exp freq A1A1; exp freq A1A2; exp freq A2A2; deltaA1A1; deltaA1A2; deltaA2A2 |
obs freq A1A1; obs freq A1A2 |
| freq A2 |
none |
obs freq A1A2; obs freq A2A2 |
| exp freq A1A1 |
none |
freqA1 |
| exp freq A1A2 |
none |
freqA1 |
| exp freq A2A2 |
none |
freqA1 |
| deltaA1A1 |
none |
freqA1; total N; genotypeA1A1 |
| deltaA1A2 |
none |
freqA1; total N; genotypeA1A2 |
| deltaA2A2 |
none |
freqA1; total N; genotypeA2A2 |
- Once we have our arrows placed, we are now in position to enter the equations for each variable. If we don't have the arrows correct, we won't be able to put the right equations in, so pay careful attention.
- Remember, to enter equations, click on the Equations icon and then click on the variable whose info you want to edit. In the box that pops up, you enter the correct information for that variable. We have a lot of variables so let's take this slowly.
- Let's start with the variables that we are just setting a value to initiate the model. For these, the equation is simple, it's just the starting value we are choosing to use. Use the following equations for these variables:
| Variable |
Parameter |
Value |
| initial N |
Equations |
10000 |
| initial freq A1A1 |
Equations |
0.4 |
| initial freq A1A2 |
Equations |
0.4 |
| initial freq A2A2 |
Equations |
0.2 |
- Next up, the 'total N' variable! You should be able to guess what the equation for this one will be... we want to know how many individuals of all genotypes are present so what should we add up? Discuss with your partner and enter your equation into the box for 'total N'. Click OK to save and close the popup box.
- Having set up 'total N' and the initial variables, we can enter the initial values for the genotypes. We already entered a value for the frequency of each genotype so to get how many individuals of each are present, we just need to multiply the initial frequency by the total N value.
- Click on 'genotypeA1A1'. What should you enter for the initial value?
- Make sure you do NOT change the equation entry for the genotypes, that is already set up correctly to be the value of the flow.
- Now that we have the genotypes set up, we can put in the equations for each observed genotype frequency (obs freq A1A1, obs freq A1A2, obs freq A2A2). If we know how many individuals there are in the population and we know how many there are of genotype A1A1, what is the equation to get the observed genotype frequency?
- Example: obs freq A1A1 equation = genotypeA1A1 / total N
- And the observed genotype frequencies are used to get the freqA1 and freqA2, the allele frequencies! We can just sum up genotype frequencies. For A1, all of the A1A1 individuals and half of the A1A2 individuals carry A1 alleles so we get:
- freqA1 = obs freq A1A1 + 0.5 * obs freq A1A2
- Go ahead and set the equation for freqA2 too!
- Once we have the allele frequencies, we can figure out how many of each genotype we PREDICT from Hardy-Weinberg (compared to what was observed). So we can set up our expected genotype frequencies (exp freq A1A1, exp freq A1A2, exp freq A2A2). For these, we should use the HW model to predict the expected genotype frequencies so what equations do we use?
- Example: exp freq A1A1 equation = p * p = freqA1 * freqA1
- Set up the equations for A1A2 and A2A2 as well.
- Finally, we are ready to put in equations for the delta values (deltaA1A1, deltaA1A2, deltaA2A2). These are our expectations given the allele frequencies and assuming Hardy-Weinberg conditions, but we also want to convert them into numbers not just frequencies AND we need to subtract the current value of that genotype stock so that we are just getting the change, not adding this value on top of the other one.
- Example: deltaA1A1 = (freqA1 * freqA1 * total N) - genotypeA1A1
- Go ahead and put in the equations for the other delta variables.
- Once you have finished entering equations, check to make sure they are correct (you may want to use the key at the end). Then we are ready to click Simulate to run the model. To get a graph, hold down Shift while you click on the things you want to show on one graph (in this case, the 3 observed genotype frequencies) and then click Graph.
- What happened? Does anything change on the graphs? What did you expect to see? Consider your responses as you write up the lab exercise in the next section.